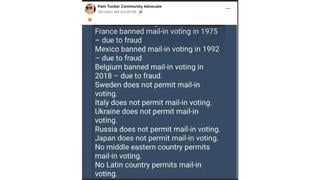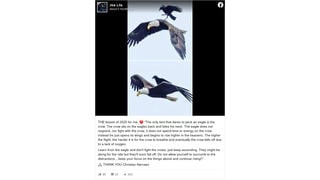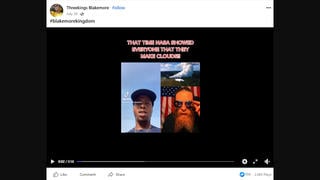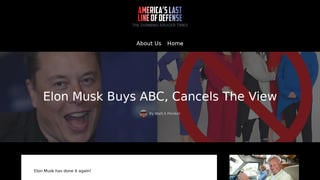
You may have noticed we've upped the tempo a bit at Lead Stories in the past few days, posting more stories per day than we used to. And you may have also noticed the images we are using to illustrate our stories have gotten a bit slicker too, with standardized font sizes for our trademark "big splashy red letters" overlay and a neat new banner at the bottom. Here's an example:
The reason is quite simple: automation. As you may be aware we are constantly hunting for trending hoaxes, fake news or (misunderstood) satire articles using our Trendolizer engine (you can read more about how we do that here). But spotting a trending story is one thing. That's when the real work starts:
- Creating a new draft post in our content management system.
- Copy-pasting the URL of the fake story into archive.is to generate an archive copy in case the original article goes down.
- Copy-pasting the resulting archive.is URL back into our own article, along with a link to the original.
- Looking up the publication date of the original story and adding it to our story.
- Taking a screenshot of the fake story and slapping a caption like "Fake!" or "Hoax!" over it in image editing software, uploading it into our CMS, fitting it into an article.
- Copy-pasting the headline of the article we're debunking into our own "Title" field, prepending "Fake News:" to it and inverting the meaning.
- Copy-pasting a few relevant paragraphs of the original story into a blockquote.
- Maybe copy-paste the URL of the original story into an embed.ly widget so our readers can see what the story would look like when viewed in isolation on social media.
- Copy-pasting the claim or headline, URL and source name of the original story into a set of fields used to generate ClaimReview markup.
- Looking up the special hash code of the original story in our Trendolizer engine so we can copy-paste it into another field that generates the graphs with the evolution of the number of likes over time of the original story.
And that's before we even get round to actually writing down why the story is false (or true...) based on reverse image searches, satire disclaimers, provable inconsistencies, direct contact with sources, previous hoaxes posted by the same (network of) site(s)...
In some cases doing all this prep work can take fifteen minutes or more and the actual fact check can suffice with: "...and there was a satire disclaimer on the site that originally posted the story so it wasn't true."
We're happy to say that we've now automated most of this process. Just by copy-pasting in the link and clicking one button we can now generate a complete 'skeleton' article about a story we want to debunk, with all fields filled in, screenshots, widgets and archive links prepared and ready to go and (in some cases) a copy of the satire disclaimer of the debunked site already copy-pasted into the article.
All that is left to do is fill in the research and conclusion, i.e. the most interesting part of doing an article.
Note that this doesn't mean our stories get written and published automatically by a bot from now on. Each article is still worked on by a human author who gets the final say on when and how to publish something. But now we can work much faster: in some cases we can now find out about a trending satire article and have a fact check out in under two minutes. We think that's nice.
And for articles involving a bit more research we now save a lot of time by no longer having to copy-paste things into various fields for fifteen minutes first, leaving more time for research.
Hooray for automation!